Spatiotemporal Face Alignment for Generalizable Deepfake Detection
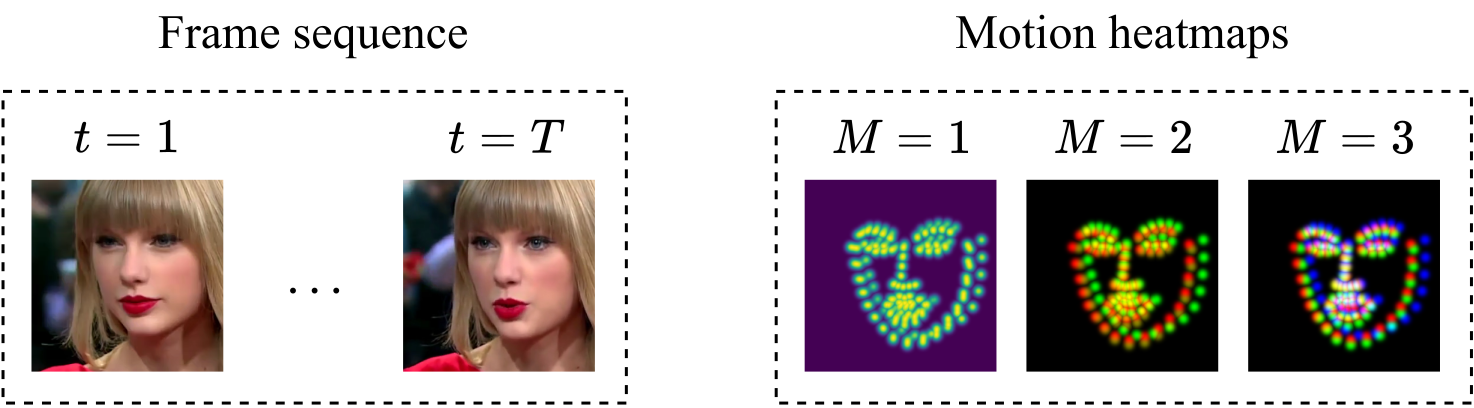
In this paper we propose a multi-task network which leverages spatiotemporal features extracted from video inputs to provide more robust predictions compared to image-only models.
In this paper we propose a multi-task network which leverages spatiotemporal features extracted from video inputs to provide more robust predictions compared to image-only models.